Guide de bonnes pratiques sur la gestion des données de la recherche#
version 2.0 - Janvier 2023
De l’importance des données de la recherche
La gestion rigoureuse et cohérente des données de la recherche constitue aujourd’hui un enjeu de taille pour la production de nouvelles connaissances scientifiques. Guidés par le « Plan National pour la Science Ouverte », les différents organismes de recherche et les Instituts du CNRS s’emparent de ces questions primordiales pour participer à la réflexion et à la mise à dispositions des outils, méthodes et infrastructures répondant aux besoins des communautés scientifiques en matière de gestion et de partage des données scientifiques.
Améliorer les pratiques de gestion des données de la science devient nécessaire pour garantir l’intégrité scientifique et la traçabilité de la recherche produite, mais aussi pour rendre accessible, partager, permettre la réutilisation ou la reproductibilité des données, qui on peut le rappeler sont financées à plus de 50% sur des fonds publics.
Gérer les données de la recherche est un processus complexe qui suppose un travail long et coûteux, des moyens techniques et humains parfois importants et qui comprend plusieurs étapes avant d’aboutir à la publication et l’archivage de données fiables, de qualité, respectueuses du droit des personnes et de la législation en vigueur.
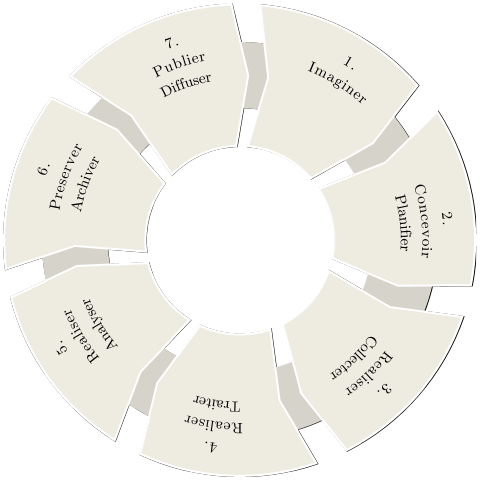
Fig. 1 Cartographie des actions des réseaux métiers autour de la gestion des données.#
Pour formaliser les différentes étapes de gestion des données, nous nous sommes servis du “cycle de vie des données” élaboré au sein de l’Atelier Données. Il s’agit d’un cercle vertueux que l’on peut faire correspondre aux différentes phases d’un projet scientifique.
L’apport des réseaux métiers du CNRS
Dans leurs différentes pratiques, les réseaux métiers du CNRS, regroupés au sein de la Mission pour les Initiatives Transverses Interdisciplinaires (MITI) ou soutenus par les Instituts sont en première ligne pour participer à ce mouvement d’ouverture et de partage des données. Les personnels des organismes de recherche qui les constituent, œuvrent pour mettre en place de bonnes pratiques de gestion et participent également au processus de production des données scientifiques aux côtés des équipes de recherche. C’est aussi dans ce cadre qu’ils interviennent en appui et en soutien à la recherche scientifique.
C’est précisément de ce travail de soutien que nous proposons de rendre compte dans ce document qui, à travers de nombreux séminaires communications et formations, vise à fournir les meilleures pratiques du moment en matière de gestion des données, et peut ainsi s’apparenter à un “guide de bonnes pratiques”.
Certes de nombreux guides existent déjà dans le domaine, mais l’originalité de ce document réside dans son application aux données de la recherche sous l’angle de différents métiers de la recherche. Il fournit donc un point de vue transversal intéressant et traduit les efforts et le soutien mis en place par les personnels d’appui à la recherche au sein des réseaux, dans la gestion et la valorisation des données scientifiques.
Objectifs du guide
Ce guide est la production du groupe de travail inter-réseaux “Atelier Données”. Il s’agit d’un groupe composé de plusieurs réseaux métiers de la MITI (Calcul, Devlog, QeR, rBDD, Renatis, Resinfo, Medici), du réseau SIST, (labellisé par l’INSU et regroupant les gestionnaires de données environnementales), de l’INIST, et de la Direction des données ouvertes de la recherche (DDOR-CNRS). Les activités du groupe ont été présentées lors d’une réunion de coordination des réseaux de la MITI en octobre 2022
Ce guide fait suite à un premier travail très synthétique réalisé en 2017 qui visait à établir une cartographie de l’action des réseaux en matière de gestion des données de la recherche. Ce travail rendait compte dans ses grandes lignes, des usages et des questionnements des réseaux sur la gestion des données, tout en apportant une vision des métiers transversale sur le sujet et les problématiques attenantes.
Il nous est apparu opportun d’aller plus loin et de détailler plus précisément les apports de nos réseaux métiers, compte tenu :
des nombreuses actions de formation ou de sensibilisation mises en place,
des compétences et expertises développées prenant appui sur des pratiques standardisées qui font leurs preuves sur le terrain,
de la diffusion de recommandations et de solutions techniques et organisationnelles au sein des communautés grâce à la veille technologique et juridique réalisée très régulièrement.
Dans ce document, nous avons donc voulu témoigner des travaux réalisés au sein de nos réseaux métiers qui rendent compte de la gestion des données de la recherche tout en guidant le lecteur vers des bonnes pratiques en l’invitant aussi à cliquer sur des liens qui constituent des ressources lui permettant d’approfondir le sujet.
Ce guide est donc un document un peu hybride proche du vadémécum, composé d’un inventaire d’actions de formations (conférences, séminaires, présentations), d’un répertoire de liens, de recommandations professionnelles, complétées de définitions utiles, pour approfondir le sujet de la gestion des données dans les réseaux métiers.
Il s’adresse à toute personne désireuse de se former à la gestion des données de la recherche, et son objectif et d’aider le lecteur à analyser son besoin et trouver des solutions parmi l’eventail des communications qui sont présentées. Il constitue aussi une invitation à se rapprocher des réseaux métiers.
Sommaire
Ce guide abordera l’ensemble des phases et actions nécessaires pour une gestion des données en accord avec les prérogatives de la science ouverte :
Les deux premières phases 1 “Imaginer et préparer” et 2 “Concevoir et planifier”, sont les étapes préparatoires d’un projet, où l’on se préoccupe d’avoir toutes les informations nécessaires à la bonne gestion des données et du projet. C’est l’étape où l’on réfléchit au plan de gestion de données, où l’on prépare les espaces de stockage et où l’on met en place les outils de gestion de projet. Cette partie, très générique, a pour objectif de conduire le lecteur à s’interroger sur ses besoins, les moyens dont il dispose, à se poser les bonnes questions et à s’orienter pour trouver des solutions adaptées dans un environnement riche, en construction et à surveiller.
Les phases suivantes apportent des éléments plus spécifiques au lecteur pour répondre à des besoins plus techniques
La phase 3 “Collecter” rend compte de la pratique de collecte et du processus d’acquisition des données (équipements, capteurs …). Elle informe tout particulièrement sur l’usage des normes et standards d’interopérabilité nécessaires à la constitution des jeux de données pour les rendre Faciles à trouver, Accessibles, Interopérables, et Réutilisables (FAIR). Elle apporte aussi un éclairage sur les environnements de stockage des données existants et la nécessité de sauvegarder des données.
La phase 4 “Traiter” témoigne du prétraitement des données brutes acquises et collectées précédemment. Elle guide le lecteur sur la nécessaire préparation des fichiers de données pour les rendre ouverts et interopérables. La connaissance et la maîtrise des formats et standards est importante. Cette étape est également celle de l’organisation des données qui implique dans certains cas de développer des procédures d’intégration des données dans les bases de données ou d’utiliser un cadre d’application d’agrégation de données. Il est important aussi à ce stade de se préoccuper du dépôt des données dans des plateformes de gestion locales [1] qui facilitent leur accès pour les scientifiques, et de mettre en place un contrôle qualité.
La phase 5 “Analyser” est la phase d’analyse dans laquelle on s’occupe de définir et mettre en place des chaines logicielles avec des méthodes et des outils. Cette partie informe le lecteur sur les plateformes, outils et méthodes utilisés principalement dans la communauté du calcul pour analyser et visualiser les données. Elle présente également quelques projets d’analyse sémantiques de données textuelles ainsi que des services Text and Data Mining.
La phase 6 “Préserver et archiver” rend compte de l’importance de préserver et archiver les données sur le long terme. On s’attache dans cette partie a bien définir et clarifier les termes, réfléchir aux données pertinentes à préserver et voir quelles solutions s’offrent à nous.
La phase 7 “Publier et diffuser” est la phase finale permettant de diffuser les données correctement à travers des catalogues de données, des thesaurus de mots clés fournissant une interopérabilité sémantique, des identifiants pérennes et des entrepôts de données, des datapapers.
Deux annexes reprennent des thèmes transverses à ces phases successives :
L’annexe “Infrastructures” décrit le paysage des infrastructures destinées à la recherche scientifique et accessibles à la communauté scientifique qui travaille en France. Le recensement est loin d’être exhaustif mais a pour objectif de fournir un aperçu des différents types d’infrastructures et d’en présenter certaines plus en détail au travers des exposés réalisés lors d’événements organisés par les réseaux.
L’annexe “Reproductibilité” rassemble des exposés concernant la reproductibilité et la répétabilité, sujets transverses à plusieurs phases. Comme dans l’ensemble de ce guide, les présentations référencées ont été réalisées dans le cadre de journées ou ateliers organisés par les réseaux.
Ce guide a été rédigé par quelques réseaux métiers et de ce fait n’a pas la prétention d’être exhaustif. D’autres contributions peuvent être mises à profit pour l’alimenter. Nous invitons donc les réseaux concernés par la gestion des données à nous faire remonter leurs pratiques métier. Nous invitons égalemement ceux qui le souhaitent à partager tous commentaires, remarques ou suggestions qui seraient de nature à améliorer et compléter ce travail, en envoyant un mail sur la liste de contact du guide.